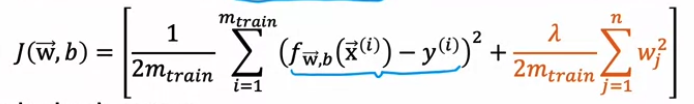#2. Anomaly detection ▶️ Finding unusual events 새로운 데이터셋이 기존의 데이터 plot과 유사한 곳에 있지 않을 경우, anomaly 하다고 판단할 수 있다 Density estimation 기존 데이터로 모델 P(x)를 학습시킨 이후 새로운 X가 데이터셋에서 나타날 확률을 P(X)라고 한다. 이때 P(X)가 epsilon(작은수)보다 작을 경우 anomaly로 분류한다 ▶️ Gaussian (normal) distribution 정규분포! 평균(Mu), 표준분포(sigma, 분산은 sigma**2)로 이뤄진 종모양 분포 x의 확률을 구하는 식은 p(x)이며, x가 중심에서 멀어질수록 p(x)도 낮아진다. Parameter estimation dataset이 주어졌..