728x90

#9. Machine learning development process
Iterative loop of ML development

Error analysis
- 에러들 (분류의 경우 잘못 분류된 예시들)을 에러들 간의 common traits 들로 카테고리화 해보는 것
- 해당 카테고리 중 에러 해결의 중요도, 에러들의 수 들을 검토하여 순차적으로 해결
→ model, data를 어떻게 설정해야 할지 인사이트를 얻을 수 있음
Adding data
- Add more data of the types where error analysis has indicated it might help
- Data augmentation: Distortion for Image , Audio (noise) , etc
- doesn't help to add purely random, meaningless noise
- Data synthesis: photo OCR의 경우, 컴퓨터 폰트에 다양한 변화를 주며 임의 데이터 생성
→ Engineering the data used by your system
- Code (Algorithm/model)
- Data centric approach
Transfer learning : using data from a different task
1. Pre training - 기존에 많은 데이터로 잘 학습된 파라미터들을 다운 받아 적용하는 것 (단 적용하려는 것과 같은 input type이어야 함)
- 이미지넷, BERT etc
2. Fine tuning - train output layers parameter
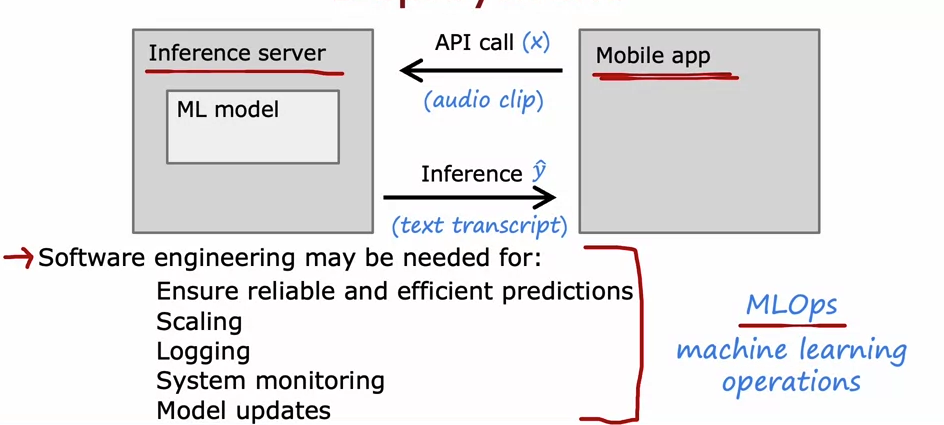
Full Cycle of a ML project

Deployment : swe가 필요한 부분 (=MLOps)
Optional . Skewed dataset
실 데이터는 skewed 된 경우가 많음 (ex. 희귀병 판별)
알고리즘 - 실제 결과 간 결과를 비교하면 다음과 같음 (가설검증 1종 오류, 2종 오류 생각하면 될듯)
→ 알고리즘 성능이 좋고 에러가 무족권 작다 라고 나오는 경우 precision과 recall 을 확인해보면 됨

하지만 Precision - Recall 은 반비례 관계에 있음. 문제의 성격에 따라 무엇을 취할 지 결정해야 함

F1 Score : precision / recall를 비교하여 좋은 알고리즘을 고르게 해줌

'👩💻LEARN : ML&Data > Lecture' 카테고리의 다른 글
| [Unsupervised Learning, Recommenders, Reinforcement Learning] #1. Clustering (0) | 2023.03.28 |
|---|---|
| [Advanced Learning Algorithms] #10. Decision Trees (0) | 2023.03.28 |
| [Advanced Learning Algorithms] #8. Bias and variance (0) | 2023.03.28 |
| [Advanced Leaning Algorithms] #7. Advice for applying machine learning (0) | 2023.03.28 |
| [Advanced Leaning Algorithms] #6. Additional Neural Network (0) | 2023.03.27 |