728x90
Evaluating a model
Train / test procedure for linear regression (with squared error cost)
- Fit parameter by minimizing cost function
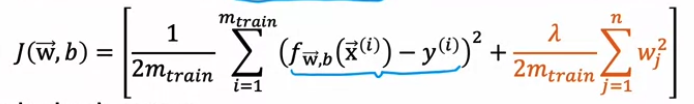
- Compute test error & training error / regularization 포함 X. regularization : 파라미터 핏을 미니마이즈하는거기때문

Train / test procedure for classification probelm
- Fit parameters by minimizing J(w,b) to find w,b
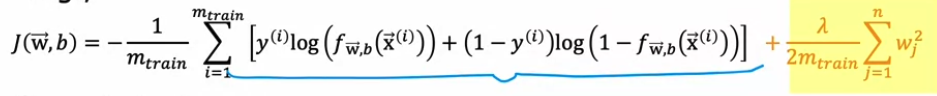
- Compute test error & train error → 분류는 이것보다 더 좋은 방법이 있음

- Fraction of the test set vs Fraction of the train set that algorithms has misclassified
- Test set과 trainset 에서 잘못 분류된 것을 찾는 것 (1이어야 하는데 0이었다거나..)
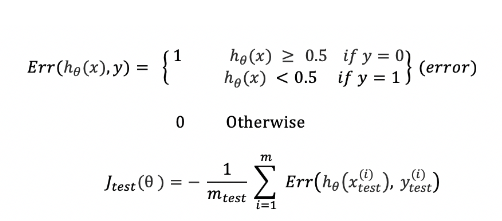
가설함수가 잘 분류했다면 오차를 0으로 가정
Model selection and training / cross validation / test sets
1. 데이터를 세개로 분류 (training : cross validation : test, 6:2:2 정도)
- cross validation : check the validity
2. 각 셋 별로 error를 계산
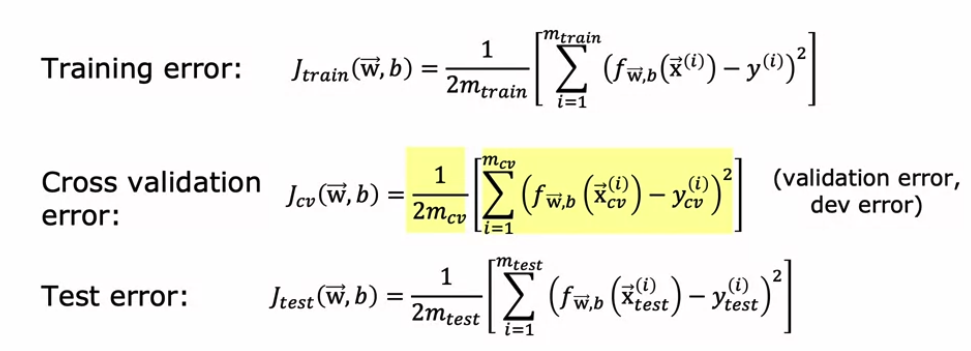
3. Model 마다 cross validation 에러 중 가장 적은 모델을 선택한 다음 테스트셋에서 동일한 모델을 테스트
위의 내용들을 코드로 구현해보자..!
1️⃣Linear Regression
#1. 데이터 나누기
# Get 60% of the dataset as the training set. Put the remaining 40% in temporary variables: x_ and y_.
x_train, x_, y_train, y_ = train_test_split(x, y, test_size=0.40, random_state=1)
# Split the 40% subset above into two: one half for cross validation and the other for the test set
x_cv, x_test, y_cv, y_test = train_test_split(x_, y_, test_size=0.50, random_state=1)
#2. 모델 만들기
# Initialize lists containing the lists, models, and scalers
train_mses = []
cv_mses = []
models = []
scalers = []
# Loop over 10 times. Each adding one more degree of polynomial higher than the last.
for degree in range(1,11):
#2.1 데이터 분포 상 선형회귀가 아닌 polinomial적용해주기 (10제곱까지 루프)
# Add polynomial features to the training set
poly = PolynomialFeatures(degree, include_bias=False)
X_train_mapped = poly.fit_transform(x_train)
#2.2 Feature Scaling
# Scale the training set
scaler_poly = StandardScaler()
X_train_mapped_scaled = scaler_poly.fit_transform(X_train_mapped)
scalers.append(scaler_poly)
#2.3 모델 생성
# Create and train the model
model = LinearRegression()
model.fit(X_train_mapped_scaled, y_train )
models.append(model)
#2.4 MSE 계산 (training set, cv set 모두 적용)
# Compute the training MSE
yhat = model.predict(X_train_mapped_scaled)
train_mse = mean_squared_error(y_train, yhat) / 2
train_mses.append(train_mse)
# Add polynomial features and scale the cross validation set
poly = PolynomialFeatures(degree, include_bias=False)
X_cv_mapped = poly.fit_transform(x_cv)
X_cv_mapped_scaled = scaler_poly.transform(X_cv_mapped)
# Compute the cross validation MSE
yhat = model.predict(X_cv_mapped_scaled)
cv_mse = mean_squared_error(y_cv, yhat) / 2
cv_mses.append(cv_mse)
#3. 베스트 모델 찾기
# Get the model with the lowest CV MSE (add 1 because list indices start at 0)
# This also corresponds to the degree of the polynomial added
degree = np.argmin(cv_mses) + 1
#4.Test set에 적용하여 Generalized MSE 확인하기
# Add polynomial features to the test set
poly = PolynomialFeatures(degree, include_bias=False)
X_test_mapped = poly.fit_transform(x_test)
# Scale the test set
X_test_mapped_scaled = scalers[degree-1].transform(X_test_mapped)
# Compute the test MSE
yhat = models[degree-1].predict(X_test_mapped_scaled)
test_mse = mean_squared_error(y_test, yhat) / 2
2️⃣ Neural Network 에서 위의 내용 구현하기
- Neural Network 에서는 polynomial 을 스킵해도 되지만 우선 학습 상 포함하여 진행
- 뉴럴 네트워크는 선형 관계가 아니기 때문에 굳이 제곱 더할 필요가 없음
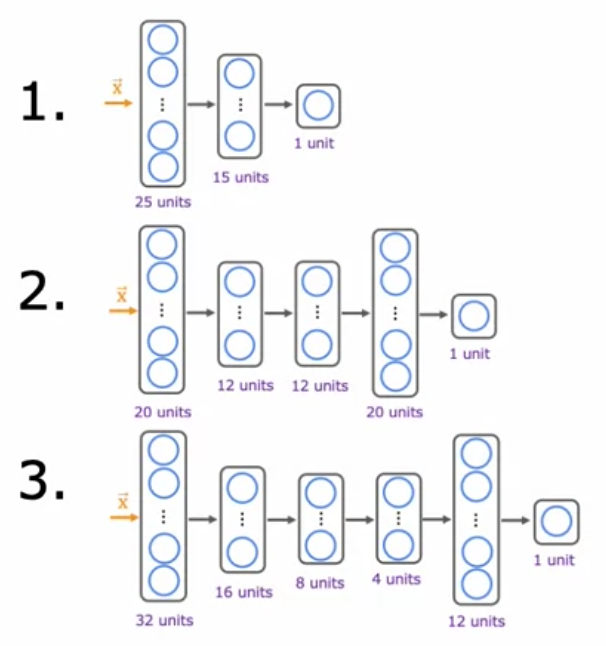
#1. 데이터 준비
#1.1 Polynomial 더하고 싶으면 아래에서 degree 변경
# Add polynomial features_ degree를 우선 1로 줘서 제곱을 더하진 않았음
degree = 1
poly = PolynomialFeatures(degree, include_bias=False)
X_train_mapped = poly.fit_transform(x_train)
X_cv_mapped = poly.transform(x_cv)
X_test_mapped = poly.transform(x_test)
#1.2 Scaling
# Scale the features using the z-score
scaler = StandardScaler()
X_train_mapped_scaled = scaler.fit_transform(X_train_mapped)
X_cv_mapped_scaled = scaler.transform(X_cv_mapped)
X_test_mapped_scaled = scaler.transform(X_test_mapped)
#2. Modeling : neural network 모델링은 코세라에서 제공하는 유틸로 대체(복잡하니까..)
# Initialize lists that will contain the errors for each model
nn_train_mses = []
nn_cv_mses = []
# Build the models
nn_models = utils.build_models()
# Loop over the the models
for model in nn_models:
# Setup the loss and optimizer
model.compile(
loss='mse',
optimizer=tf.keras.optimizers.Adam(learning_rate=0.1),
)
print(f"Training {model.name}...")
# Train the model
model.fit(
X_train_mapped_scaled, y_train,
epochs=300,
verbose=0
)
print("Done!\n")
# Record the training MSEs
yhat = model.predict(X_train_mapped_scaled)
train_mse = mean_squared_error(y_train, yhat) / 2
nn_train_mses.append(train_mse)
# Record the cross validation MSEs
yhat = model.predict(X_cv_mapped_scaled)
cv_mse = mean_squared_error(y_cv, yhat) / 2
nn_cv_mses.append(cv_mse)
# print results
print("RESULTS:")
for model_num in range(len(nn_train_mses)):
print(
f"Model {model_num+1}: Training MSE: {nn_train_mses[model_num]:.2f}, " +
f"CV MSE: {nn_cv_mses[model_num]:.2f}"
)
#3. Best Model
# Select the model with the lowest CV MSE
model_num = 3
# Compute the test MSE
yhat = nn_models[model_num-1].predict(X_test_mapped_scaled)
test_mse = mean_squared_error(y_test, yhat) / 2
print(f"Selected Model: {model_num}")
print(f"Training MSE: {nn_train_mses[model_num-1]:.2f}")
print(f"Cross Validation MSE: {nn_cv_mses[model_num-1]:.2f}")
print(f"Test MSE: {test_mse:.2f}")3️⃣Classification
- 분류에서는 MSE가 아니라 분류를 잘못한 비율을 확인하는 것을 유의
#1. 데이터 준비
# Load the dataset from a text file
data = np.loadtxt('./data/data_w3_ex2.csv', delimiter=',')
# Split the inputs and outputs into separate arrays
x_bc = data[:,:-1]
y_bc = data[:,-1]
# Convert y into 2-D because the commands later will require it (x is already 2-D)
y_bc = np.expand_dims(y_bc, axis=1)
print(f"the shape of the inputs x is: {x_bc.shape}")
print(f"the shape of the targets y is: {y_bc.shape}")
#1.1 데이터 분리 : train, cv, test
from sklearn.model_selection import train_test_split
# Get 60% of the dataset as the training set. Put the remaining 40% in temporary variables.
x_bc_train, x_, y_bc_train, y_ = train_test_split(x_bc, y_bc, test_size=0.40, random_state=1)
# Split the 40% subset above into two: one half for cross validation and the other for the test set
x_bc_cv, x_bc_test, y_bc_cv, y_bc_test = train_test_split(x_, y_, test_size=0.50, random_state=1)
# Delete temporary variables
del x_, y_
#2. 예시 : Error 계산은 아래처럼 진행할 예정
# Sample model output
probabilities = np.array([0.2, 0.6, 0.7, 0.3, 0.8])
# Apply a threshold to the model output. If greater than 0.5, set to 1. Else 0.
predictions = np.where(probabilities >= 0.5, 1, 0)
# Ground truth labels
ground_truth = np.array([1, 1, 1, 1, 1])
# Initialize counter for misclassified data
misclassified = 0
# Get number of predictions
num_predictions = len(predictions)
# Loop over each prediction
for i in range(num_predictions):
# Check if it matches the ground truth
if predictions[i] != ground_truth[i]:
# Add one to the counter if the prediction is wrong
misclassified += 1
# Compute the fraction of the data that the model misclassified
fraction_error = misclassified/num_predictions
#3. 모델 만들고 에러 계산하기
# Initialize lists that will contain the errors for each model
nn_train_error = []
nn_cv_error = []
# Build the models
models_bc = utils.build_models()
# Loop over each model
for model in models_bc:
# Setup the loss and optimizer
model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
)
print(f"Training {model.name}...")
# Train the model
model.fit(
x_bc_train, y_bc_train,
epochs=200,
verbose=0
)
print("Done!\n")
# Set the threshold for classification
threshold = 0.5
# Record the fraction of misclassified examples for the training set
yhat = model.predict(x_bc_train)
yhat = tf.math.sigmoid(yhat)
yhat = np.where(yhat >= threshold, 1, 0)
train_error = np.mean(yhat != y_bc_train)
nn_train_error.append(train_error)
# Record the fraction of misclassified examples for the cross validation set
yhat = model.predict(x_bc_cv)
yhat = tf.math.sigmoid(yhat)
yhat = np.where(yhat >= threshold, 1, 0)
cv_error = np.mean(yhat != y_bc_cv)
nn_cv_error.append(cv_error)
# Print the result
for model_num in range(len(nn_train_error)):
print(
f"Model {model_num+1}: Training Set Classification Error: {nn_train_error[model_num]:.5f}, " +
f"CV Set Classification Error: {nn_cv_error[model_num]:.5f}"
)
#4. 모델 선택하고 이에 따른 test set error 계산하기
# Select the model with the lowest error
model_num = 2
# Compute the test error
yhat = models_bc[model_num-1].predict(x_bc_test)
yhat = tf.math.sigmoid(yhat)
yhat = np.where(yhat >= threshold, 1, 0)
nn_test_error = np.mean(yhat != y_bc_test)