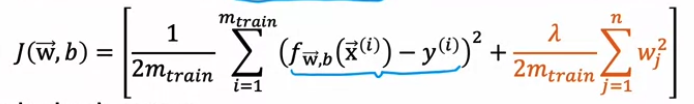Evaluating a model Train / test procedure for linear regression (with squared error cost) Fit parameter by minimizing cost function Compute test error & training error / regularization 포함 X. regularization : 파라미터 핏을 미니마이즈하는거기때문 Train / test procedure for classification probelm Fit parameters by minimizing J(w,b) to find w,b Compute test error & train error → 분류는 이것보다 더 좋은 방법이 있음 Fraction of the ..