728x90

#2. State-action value function
▶️ State-action value function definition (=Q function, Q*)
- Q(s,a) = total return if you starts in state s take action a (once) then behave optimally after that

Picking actions
- state s에서는 Q(s,a)를 최대화할 수 있는 행동이 가장 좋음
▶️ Bellman Equation

- s',a' : s,a 이후의 state, action
- terminal state에서의 Q(s,a) = R(s)임

▶️ Random(stochastic) environment
Expected Return → 최대로 할 수 있어야 함
잘못 행동할 확률에 대한 값을 넣는 것도 가능

#3. Continuous state spaces
▶️ Example of continuous state space applications
Discrete vs Continuous state
- 이동은 사실 연속적으로 이루어지게 됨
- 이에 차의 state는 x, y, theta, x의 변화 속도,y의 변화 속도, theta의 변화속도로 구성된 벡터가 됨
- 헬리콥터의 경우 3D이므로 position x,y,z, angle 3개와 이 여섯개에 대한 변화속도로 구성된 벡터가됨
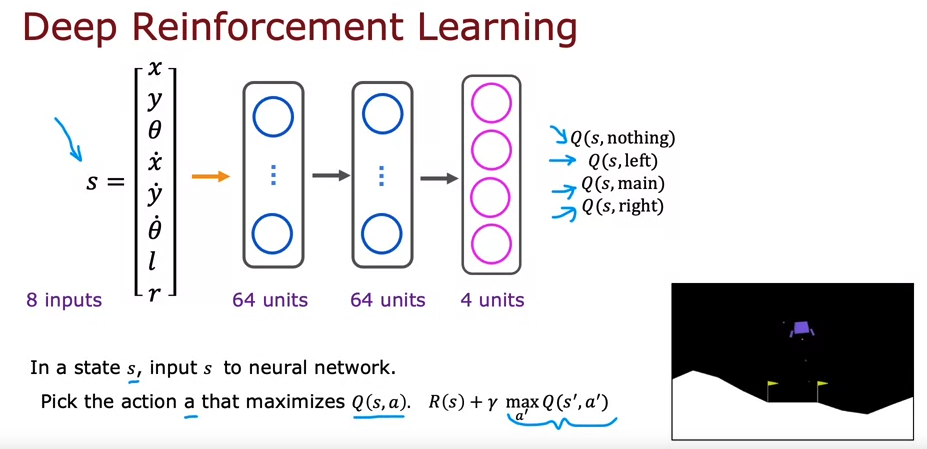
▶️ Lunar Lander
- action: do nothing, left thruster, main thruster, right thruster, →one-hot 인코딩 할 것
- states = [x,y,x velocity, y velocity, angle, angle velocity, l:left grounded, r:right grounded] /l,r = binary
- reward function

▶️ Learning the state-value function
개요
- s,a에 대한 벡터 x를 Input으로 뉴럴네트워크에 넣는다
- state는 그대로 넣고 action은 원핫인코딩 시킨다

- 뉴럴네트워크를 어떻게 train시킬 수 있는가?
- Bellman 공식을 사용하여 다양한 x,y의 예시를 만들고, supervised learning을 사용하여 x-y mapping을 한다
- policy가 없으면 랜덤하게 action을 수행시키고 랜덤한 y값을 얻는다. (천개,,만개..)
- Q funcion이 무엇인지는 나중에...
- Bellman 공식을 사용하여 다양한 x,y의 예시를 만들고, supervised learning을 사용하여 x-y mapping을 한다

- Learning Algorithm
- Q(s,a)의 추측으로 뉴럴네트워크를 초기화 시킨다.
- 다음을 반복한다.
- 무작위로 action을 시켜서 s,a,R(s), s'를 여러개 얻는다. (recent 만개정도)
- 뉴럴네트워크를 train 시킨다
- 10,000개의 트레이닝셋을 만든다 x = (s,a), y = R(s)+gamma*maxQ(s',a')
- Qnew(s,a)가 y에 가깝도록 train한다
- Q = Qnew로 세팅한다
▶️ Algorithm refinement: Improved NN architecture
- output 값을 각 action에 대한 Q(s,a) 로 세팅
- 이렇게 되면 다음 액션 중 maximum Q값을 가진 액션 선택 시 보다 쉽게 고를 수 있음
▶️Algorithm refinement: ϵ-greedy policy
- 랜덤 initialize로 인해 액션 옵션 중 학습하지 않는 옵션이 생길 수 있기 때문에 Q(s,a)를 최대화 하는 옵션에 대한 가능성(Greedy, Exploitation)과 완전 랜덤한 행동을 하게 하는 가능성(Exploration)을 동시에 둔다.
- 엡실론 = exploration에 대한 것
- 처음 시행 시엔 엡실론을 높게 (1.0)주었다가 점차적으로 줄이면서 랜덤 행동을 줄이는 것도 가능하다.

▶️Algorithm refinement: Mini batch and soft updates
Mini batch
- 학습 중에 어떻게 action을 선택할 수 있는가?
- 데이터셋의 크기(m)가 매우 클 때 (100,000,000...)한번에 학습하면 매우 오래 걸림
- 이에 m'(1,000)을 작게 설정해서 여러번 학습시키는 것 (MECE하게도 가능하고 완전 랜덤하게 뽑는것도 가능)
- 이렇게 하면 방향이 슉슉 바뀔 순 있지만(noise) 빠르게 학습 가능
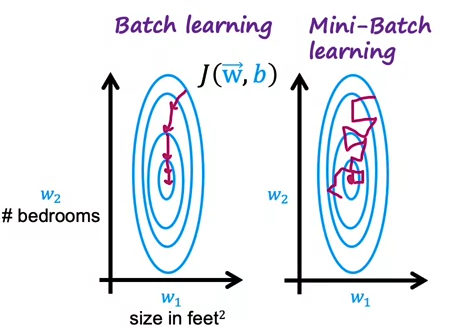
- RL에서도 트레이닝셋을 mini batch size로 설정해서 여러번 반복하면서 빠르게 학습할 수 있음
Soft updates
- Set Q = Q new 로 덮어쓰게 되면 Q new가 좋지 않은 모델일 때 오히려 돌아가는 형태가 될 수 있음
- 그러므로 w new, b new 를 천천히 업데이트 시키는 것
- w = 0.01 * w new + 0.99 w 처럼 희석시키기

일주일동안 하루에 5시간 이상씩 공부해서 수료증을 취득했다 ..!
잊어버리기 전에 코드까지 다 복습하고 구현도 해봐야겠다..바쁘다바빠...
https://www.coursera.org/account/accomplishments/specialization/certificate/NP84P7NEJZ9G
Coursera | Online Courses & Credentials From Top Educators. Join for Free | Coursera
Learn online and earn valuable credentials from top universities like Yale, Michigan, Stanford, and leading companies like Google and IBM. Join Coursera for free and transform your career with degrees, certificates, Specializations, & MOOCs in data science
www.coursera.org
'👩💻LEARN : ML&Data > Lecture' 카테고리의 다른 글
| [CS231n] Lecture2. Image Classification Pipeline (0) | 2023.05.08 |
|---|---|
| [알고리즘 구현으로 배우는 선형대수] #11. 직교 행렬 (0) | 2023.04.13 |
| [Reinforcement learning]#1. Introduction (0) | 2023.03.30 |
| [Unsupervised Learning, Recommenders, Reinforcement Learning] #4. Content-based filtering (0) | 2023.03.30 |
| [Unsupervised Learning, Recommenders, Reinforcement Learning] #3. Collaborative Filtering (0) | 2023.03.30 |