728x90
RNN 자연어처리에만 쓰일줄 알았는데 CNN이랑 같이 사용하면 캡셔닝 task 수행할 수 있어서 같이 배워야...🥲
RNN 개요
- 다양한 입출력, 그리고 Sequence를 처리할 수 있는 신경망
- 순서가 없는 데이터여도 Sequential Process를 거치는 경우가 존재하는데 이 때에도 과정이 변화하는 경우이므로 사용가능 ex.숫자 이미지 인식할 때 이미지 부분을 차례대로 살펴보며 숫자를 판단
- One to One : 일반적인 신경망으로 하나의 입력과 하나의 출력이 존재
- One to Many : 하나의 입력을 주지만 출력을 여러개인 것. ex. Image Captioning (image -> sequence of words)
- Many to One : 입력은 여러개이지만 출력은 하나인 것 ex. Sentiment Classification (sequence of words -> sentiment)
- Many to Many : 입력도 출력도 여러개... ex. Machine Translation (seq of words -> seq of words), Video classification on frame level (video frame -> classification per frame)

RNN 상세 설명
[Recurrence Formula]
- 연속해서 제공될 input x를 재귀식에 넣음으로서 매 스텝마다 업데이트할 수 있음
- ht : 새로운 상태
- f_W : W가중치를 가진 함수로 매 스텝마다 같은 파라미터를 사용할 것임
- ht-1, x_t : ht-1 이전 상태와 xt t시점에서의 인풋

- 현재 상태 ht는 사실 tanh 함수(비선형!)를 사용하며, ht-1,xt를 인풋으로 받아 각각의 가중치 W와 곱한다
- 현재 상태 ht는 이후 다른 가중치 W와 곱해서 최종 output인 yt를 산출하게 된다

[Computational Graph]
일반적인 RNN의 연산그래프는 아래와 같다.

- h0 : 최초엔 0으로 초기화된다
- 각 단계에 따라 xt가 순차적으로 입력된다
- 이 때 fw에 사용되는 가중치 W는 같은 것으로 매번 재사용된다
- Backprop 시 dLoss/dW를 계산하려면 행렬 W의 local gradient를 모두 구한 후 합하면 된다
Case of Many to Many

- 매 단계마다 y를 구하고 단계마다의 오차를 구한 뒤(step마다 ground truth가 있다는 전제), 이를 모두 합하면 총 오차가 된다
Case of Many to One

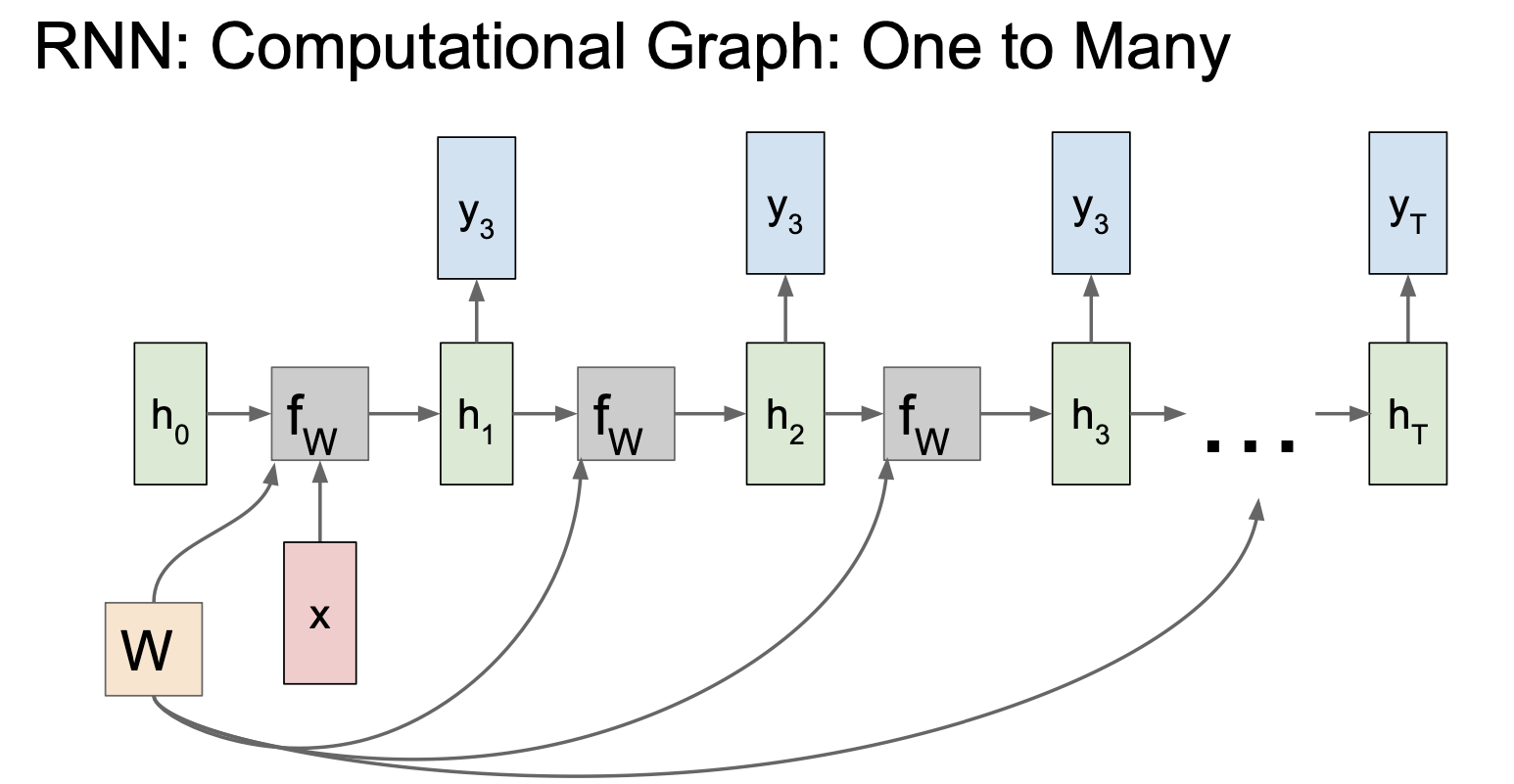
Case of One to Many
[Sequence to Sequence : Many-to-one + one-to-many]
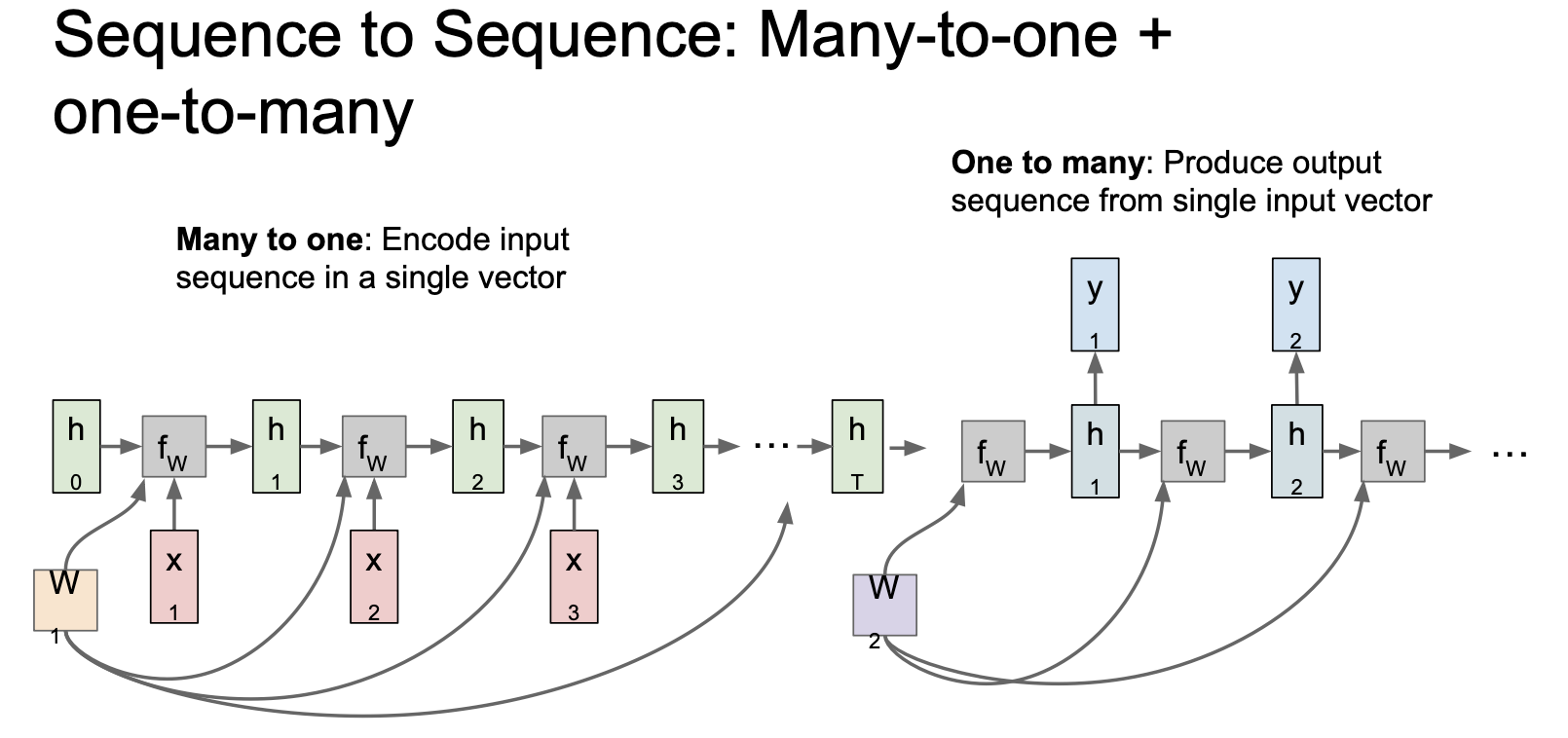
- 두개의 RNN 모델을 결합해서 사용하는 것도 가능하다.
- Many to one 에서는 여러 입력을 연산한 다음, 결과로 하나의 벡터를 산출한다. (Encoder)
- One to Many 에서는 인코더로부터 입력받은 하나의 벡터를 연산하여 여러 결과를 산출한다 (Decoder)
[Truncated BackPropagation Through the Time]

- 문제점: 자연어 처리 등에서 문서를 학습시키게 되면 스텝이 많이 길어져서 오차를 계산할 때에도, gradient를 계산할 때에도 너무 많은 시간이 소요된다.
- 해결: 학습할 sequence을 chunk로 나눠서 진행하여 근사치로 이를 수행한다
- 이전 단계의 hidden state는 계속 유지한다
- 다음 chunk에서 forward pass를 진행할 때 이전 단계의 hidden state를 함께 사용한다
- Backprop에서의 gradient는 현재 속한 chunk에서만 연산한다
[Example: character level LM]

- 문자단위로 언어모델을 만들 경우 학습단계에서는
- 인풋레이어는 원핫인코딩을 통해 더미벡터로 만들어 매 문자 단계 별로 입력을 한다
- hidden layer와의 연산을 통해 ouput layer에서 각 문자 마다의 score를 연산한다
- target과의 비교를 통해 오차를 매번 계산해주고 backprop을 통해 hidden layer의 W를 학습시킨다

- 이후 테스트 단계에서는 score에 softmax 함수를 씌워 각 후보 캐릭터들의 확률분포를 계산
- 그리고 그 확률 분포에 맞게 샘플링을 해서 다음 단어를 예측한다 (e의 확률이 o보다 낮은데 e가 나온건 샘플에서 뽑기가 잘된탓!)
- 예측된 단어를 그 다음단계의 인풋으로 줘서 이 단계를 끝날때까지 반복한다
[Example: Image Captioning]


- 이미지 캡션 작업은 CNN + RNN 결합한 것으로, CNN의 결과물(최종 레이어 제외하고!)을 hidden state의 초기값으로 전달한다.
- 이후 y0를 예측할때 모든 vocab에 대한 확률 분포를 계산한 다음 샘플링 하여(앞에 것과 동일) 다음 단계의 입력으로 준다
- 학습시킬때에 캡션 마지막에 <END>를 넣어준다 (-> 예측할 때에 끝낼때 이 조건을 넣어주게 됨)
- 이미지 캡셔닝은 Supervised 이며 image-label이 포함된 trainset이 필요함
LSTM

[문제점]
- 기존 RNN에서 자주 볼 구조는 사실 multilayer라 hidden state가 여러개임
- 이럴 때 기존 RNN Gradient Flow를 살펴보면 Vasnishing/Exploding gradient의 문제를 내포하고 있음
- ht에서 ht-1로 backprop할 때 가중치 W를 곱해주게 됨 (정확하겐 W의 전치행렬..)
- 이에 Loss에서부터 h0까지의 gradient를 계산하면 W와 tanh를 계속 곱해줘야 함
- 이 때 W 벡터에서 한 요소만이라도 1보다 크거나 1보다 작게 되면 gradient 문제가 발생
- 이를 해결하기 위해 LSTM을 사용해야 함
[개요]
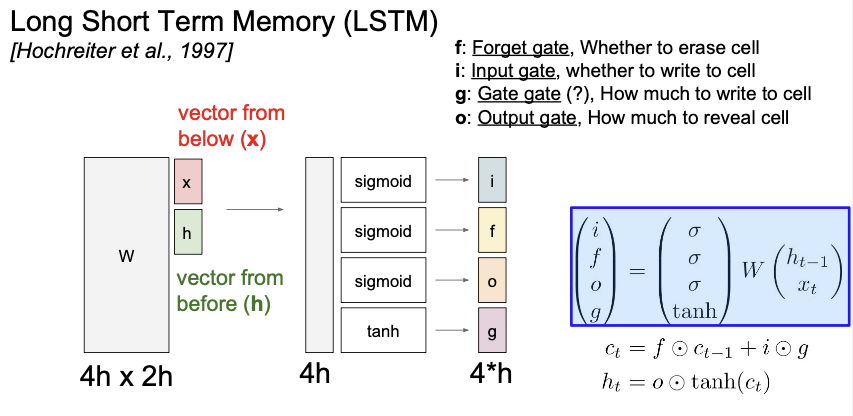
- 기존 RNN과 달리 cell state 라는 새로운 변수를 사용 (모델 내부에서만 사용)
- 이전 상태인 ht-1,입력값 x를 쌓아주고 이를 가중치 W와 곱한다.
- 이 곱한 값을 각각 시그모이드와 tanh을 곱해 i,f,o,g 값을 구한다
- ct는 forget gate와 inputgate, gate gate의 조합으로 이 값 ct를 tanh과 씌운 이후 output gate와 곱해 현재 상태를 업데이트한다

- 이를 구현하면 위의 연산그래프와 같은 형태인데, ct에서 ct-1이 될때 W가 관여하지 않으므로 gradient 연산이 매우 편리해진다!
- 진짜 구하고 싶은 W도 사실상 위의 gradient에서 f 를 미분한 단계이므로 기존 RNN보다 gradient flow가 좋음
- 이는 마치 Resnet과 같은 플로우이며 연산에 아주아주 좋다..!
'👩💻LEARN : ML&Data > Lecture' 카테고리의 다른 글
| [CS231n] Lecture11. Detection and Segmentation (1) | 2023.05.19 |
|---|---|
| [CS231n] Lecture9. CNN Architecture (0) | 2023.05.16 |
| [CS231n] Lecture8. Deep Learning SW - Pytorch (1) | 2023.05.16 |
| [CS231n] Lecture6. Training Neural Networks 2 (0) | 2023.05.15 |
| [CS231n] Lecture6. Training Neural Networks 1 (0) | 2023.05.14 |